Moving goalposts
A major enterprise pharma decides to cull 90% of AI pilots because of the 900 pilots running, only 10% were delivering real enterprise value.
This should be concerning for AI companies building in this space. How can it be that AI systems massively outperform on benchmarks and hit the technical metrics but still fail to translate that to enterprise value? AI pilots often succeed technically but fail to influence decisions, reduce cycle times, or justify continued investment.
Part of the problem is that the early wins in AI use cases have been entirely absorbed into the frontier models themselves. Document generation, literature summarization, data exploration, and other forms of procedural assistance are rapidly becoming baseline capabilities rather than differentiated products. Raising the floor of capabilities means AI companies have to tackle harder and more complex drug discovery problems. The further you are from program decisions, the less valuable the systems become, no matter how strong they perform on benchmarks.
The goalposts have shifted.
It's not about giving 100 scientists a co-pilot that makes them 30% more productive anymore. The bigger opportunity is to make the judgment of an R&D org's best scientists available across hundreds of decisions simultaneously.
The first pharma company to be able to encode scientific reasoning and judgment into substrates that humans and AI agents can understand, augment, and iterate on will unlock a fundamentally different model of AI-driven drug discovery.
But getting there requires understanding why the current agent architecture begins to break as its capabilities expand.
How do you teach AI to think like your scientists?
Drugs are the product of differentiated data and knowledge. Together, it becomes the most treasured and closely guarded resource in any serious pharmaceutical organization. They will not freely share the failed experiments, internal disagreements, proprietary datasets, decision histories, and tacit standards of evidence that distinguish how they discover drugs. Nor will they allow external vendors to train generalized models on the corpus from which their competitive advantage is derived.
This makes drug discovery a uniquely unforgiving environment for AI agents/co-scientists.
The incentives are structurally misaligned. AI companies are largely limited to public-domain training data, yet the public literature is a poor representation of how real drug-discovery decisions are made. It over-represents positive findings, omits much of the negative evidence, and strips away the organizational context, debate, and accumulated experience that determine whether a program advances or dies.
Most importantly, scientific judgment has been encoded into people, never in systems.
Capability and confusion scale together
To meaningfully participate in real-world drug discovery work, AI agents must reach beyond what models absorbed in pre-training and handle modalities beyond text. Drug discovery is inherently multimodal, requiring diverse data types, transformations, and post-processing analytics.
Frontier models are already highly capable and they will only continue to get better. Modern agentic systems are designed to give them the tools to gather context and draw conclusions. For example, much of bioinformatics procedural work can be automated by workflow and analysis agents with access to computing resources.
However, the complexity of multimodal reasoning in life sciences means these aren't one-off calls. A single question can send an agent through hundreds of files; each pass between the agent, the data, and the task consumes more tokens in the context loop. In long-running autonomous research, the promise is that the system continuously gathers context, reduces uncertainty, and converges on the best answer.
Here's where problems start. Biology is messy. Contradiction is the normal state of evidence and real insight more often comes from knowing which data to ignore and which data to pay attention to. Rarely does it come from careful rereading of the same data to uncover some universal truth.
The more powerful the system, the more it gathers; the more it gathers, the more tokens it burns and the more context entropy it generates. Latency and costs scale non-linearly, as each decision requires more context, more reasoning, and more careful selection between actions. Left unchecked, agentic systems can become a runaway cost center, earnestly burning tokens on the way to a worse answer.
The obvious response is to narrow the aperture.
Specialization becomes necessary, but not sufficient
Platforms now include sub-agents for literature search, data analysis, workflow execution, figure generation, chemistry review, and increasingly narrow scientific tasks.
Specialization works because it limits confusion.
A literature agent does not need to decide which clinical endpoint should govern a development strategy. A bioinformatics agent does not need to reason across an entire target-product profile. A chemistry agent does not need to evaluate the commercial implications of a biomarker.
Each agent operates within a narrower domain, with a smaller set of tools, a more focused context, and a clearer output.
This also makes agents easier to evaluate.
Every cycle of sub-specialization creates pressure on builders to bolt on more tools and set up more complex evaluations to demonstrate that they are "better" than SOTA on some arbitrary standard. By the end of the pilot, the system may have passed every technical metric. It may cluster single-cell data better, summarize papers faster, or retrieve more relevant documents.
But the buyer is still left asking: did this change a decision that mattered?
The problem with specialization is that drug discovery decisions are not specialized in the same way the agents are. Program decisions cut across biology, chemistry, translational evidence, safety, clinical feasibility, competitive context, and commercial strategy. The value is not created inside any one workflow. It is created in the connective tissue between them.
Specialization solves the problem of local confusion by creating a new problem of global fragmentation.
Multi-agent trap
If we have a bunch of specialized agents, the natural response is to try and connect them together. Drug program decisions are logical processes so in theory, this should be possible.
A literature agent informs a target-evaluation agent. A bioinformatics agent informs a biomarker agent. A translational agent informs a clinical-strategy agent. An internally developed system consumes the output of a vendor platform. Local conclusions become inputs into progressively larger decisions.
This only works when each agent shares a common basis of understanding.
When one agent produces an output, the next agent must understand what that output means, how it was generated, which definitions were used, what assumptions were made, what uncertainty remains, and which parts of the conclusion are reliable enough to build on.
In the absence of this shared understanding errors propagate aggressively through the system. A weak assumption in a literature review becomes an input into a target evaluation. A mislabeled dataset becomes evidence for a biomarker strategy. A noisy analytical result becomes a biological claim. A biological claim becomes an input into a translational hypothesis.
By the time the original error reaches the final answer, it has been transformed, summarized, re-aggregated, and laundered through enough intermediate reasoning steps that it appears more authoritative than it actually is.
Can we solve this with better orchestration?
Orchestration moves information and data between agents. It cannot ensure that the agents understand the information in the same way. The interfaces may be technically compatible while the underlying reasoning remains incompatible. This is particularly dangerous in drug discovery because important and commonly used terms are rarely neutral.
"Validated", "Selective", "Meaningful", "Druggable", "Acceptable risk"
Each is a conclusion built from assumptions, thresholds, evidence standards, and prior judgment. Passing these terms between agents without preserving how they were defined creates the appearance of agreement where none exists.
The challenge in coordinating agents is preserving meaning and judgment across the system.
The consequences are cumulative
- 01Frontier models become more capable, so agentic systems give them more tools and more context.
- 02More context creates more opportunity for confusion, so agents become increasingly specialized.
- 03Specialization improves local performance but fragments the decision process.
- 04Fragmentation creates pressure to chain more agents together.
- 05Each new handoff introduces another opportunity for assumptions, definitions, evidence, and uncertainty to be altered or lost.
The result is a system in which each component can pass its evaluation while the end-to-end reasoning process becomes harder to inspect, harder to trust, and harder to connect to the decision that justified building it in the first place.
Larger models do not remove the need for institutional memory
Continued improvements in model capability and context capacity will reduce some current limitations. Retrieval will improve. Tool selection will become more reliable. Longer analytical trajectories will become easier to manage.
Several problems will remain.
A model can read every document in an organization without knowing which document currently governs a decision. It can identify multiple definitions without knowing which definition applies to a specific program. It can detect contradictory conclusions without knowing whether the contradiction reflects different experimental conditions, newer evidence, or an issue already adjudicated by a governance body.
Context capacity does not establish authority, policy, or scientific meaning.
The model's interpretation may be scientifically reasonable and still conflict with the organization's accumulated experience, risk tolerance, or development strategy. Proprietary judgment will remain strategically important. Pharmaceutical companies have strong incentives to retain control over the evidence, reasoning, and decision histories that differentiate their R&D performance. Model providers have strong incentives to build broadly useful intelligence across customers and domains.
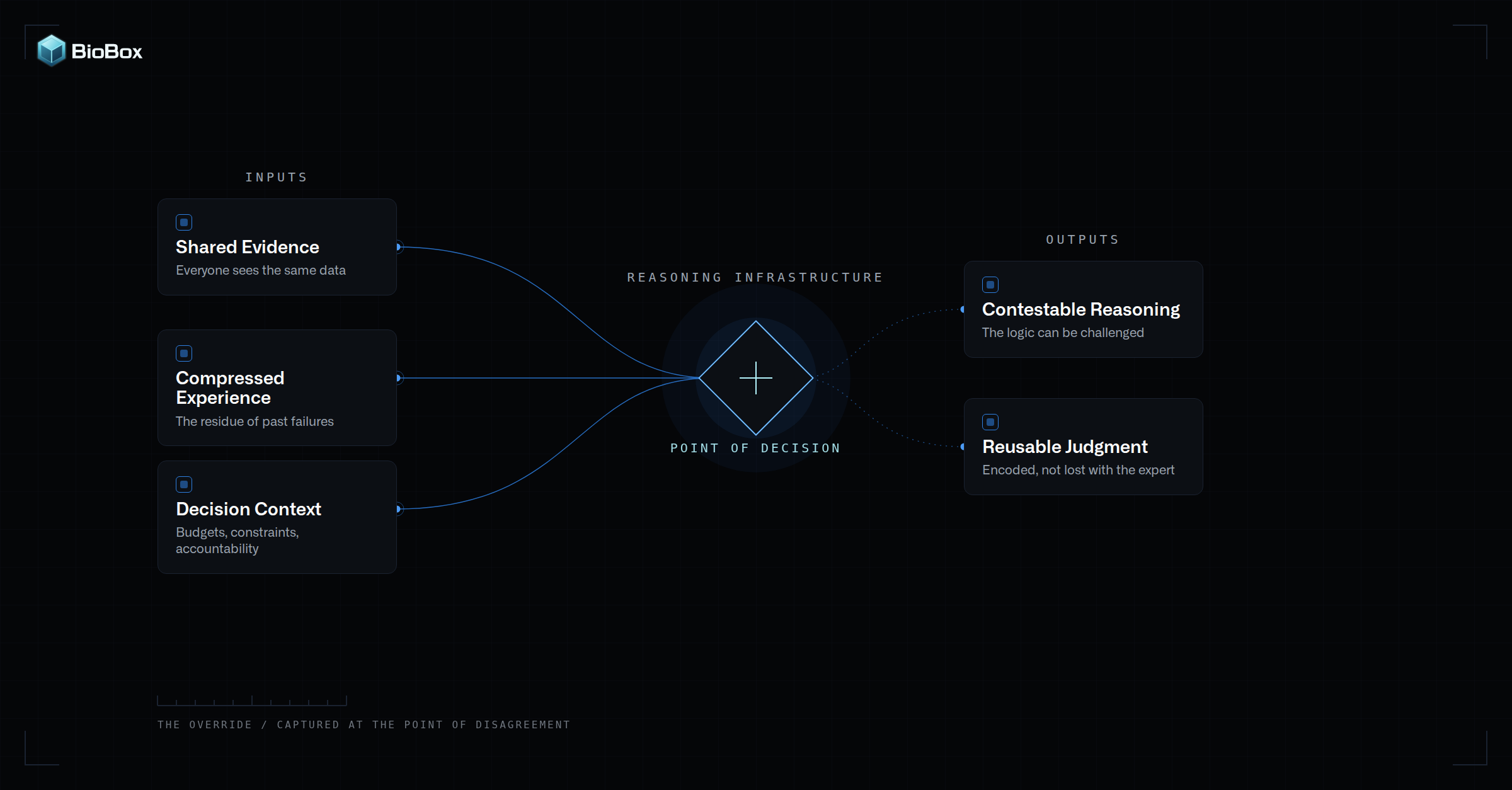
An effective architecture must respect both realities. Organizational knowledge and judgment must remain under the company's control while being represented in a form that models and agents can use.
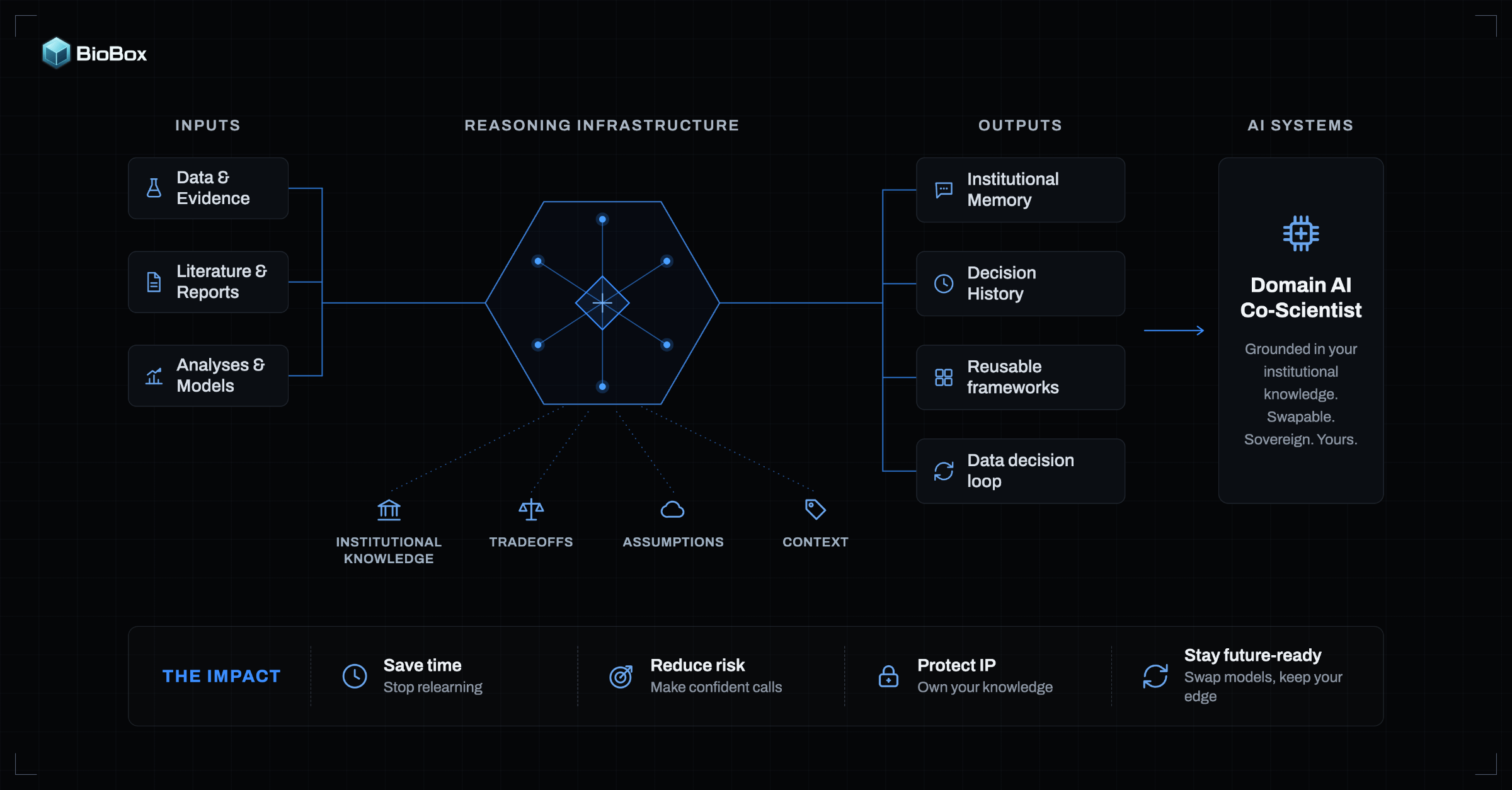
Reasoning infrastructure gives humans and agents a shared basis to operate
To overcome the limitations of current agent architectures, it must perform three interconnected functions.
1. Create shared meaning across multimodal data
Drug discovery depends on concepts that are not neutral. "Validated," "druggable," "clinically meaningful," and "acceptable risk" derive their meaning from specific evidence, experimental conditions, definitions, and organizational standards.
Reasoning infrastructure must establish a common semantic foundation across assays, omics, chemistry, clinical evidence, literature, and internal knowledge. It must allow humans and agents to understand not only that two pieces of information are related, but what the relationship means and under which conditions it remains valid.
Without shared meaning, agents can exchange technically compatible outputs while reasoning from incompatible definitions.
2. Encode scientific judgment as a programmable asset
Scientific reasoning should not remain trapped in documents, workflows, meeting notes, or individual experts.
Reasoning infrastructure must explicitly represent how conclusions are reached: the evidence considered, the assumptions made, the definitions applied, the uncertainty tolerated, the alternatives rejected, and the decision criteria used.
This turns scientific judgment into a reusable reasoning layer that humans and agents can inspect, challenge, improve, and execute against.
The objective is not to automate judgment by hiding it inside a model. It is to make judgment legible enough that people and machines can reason from the same foundation.
3. Compress complexity into decision-ready interfaces
Decision-makers rarely need every available piece of evidence. They need the evidence relevant to the decision, the assumptions governing its interpretation, the remaining uncertainty, and the rationale behind the recommendation.
Reasoning infrastructure must transform complex and distributed scientific knowledge into decision-specific views. The representation required for target selection will differ from the one required for biomarker strategy, translational planning, or portfolio prioritization, even when those decisions draw from overlapping evidence.
The goal is not to reduce the underlying science to a simplistic answer. It is to preserve its complexity while presenting the portion of that complexity required to act.
Reasoning must persist across agents, models, and time
Models will change. Agents will change. Scientific understanding will evolve.
The underlying reasoning system must remain independent of any particular model, vendor, or workflow. Conclusions must remain traceable, assumptions must remain visible, and previous judgments must be revisable as new evidence emerges.
This allows institutional knowledge to compound rather than being reconstructed with every new agent, employee, or technology cycle.
The cost of each decision must decline
Organizations do not create value by processing more information. They create value by making better decisions faster.
Every decision should leave behind structured reasoning that makes the next related decision easier. Agents should be able to build on prior evidence, definitions, and adjudicated conclusions instead of repeatedly retrieving the same information and reconstructing the same context from scratch.
Reasoning infrastructure therefore reduces cost not simply by using fewer tokens, but by eliminating redundant interpretation. As institutional reasoning compounds, the marginal cost of reaching a high-quality decision should decline.
These requirements define the architecture of reasoning infrastructure.
BioBox was built to implement that architecture across the full decision process: establishing shared scientific meaning, encoding organizational judgment, preserving reasoning over time, and delivering the right evidence and rationale to every human and agent responsible for acting on it.