What is Multi-Modal Data?
The world is rarely observed through a single form of evidence. A picture shows the appearance and a voice note reveals their voice and the words they speak reveals their intent. Each piece of information provides perspective that adds something.
This is the basic idea of multi-modal data: combining more than one dimension/form of information to get a more complete representation of the subject. In general purpose AI, we talk about multi-modality as a function of the data inputs (text, image, video, audio, and structured data). Having more of one modality has diminishing returns. The value comes from having more connected data that each displays a different dimension of reality.
In life sciences research, multi-modal data is critical to understanding how complex biological systems operate. Imaging preserves spatial orientation, structure, and morphology. Clinical EHRs document phenotypes, treatments, and health outcomes. Omic technologies capture active biological states at molecular, cellular, tissue, and organism scales.
Applied to drug discovery, multi-modal data is valuable because it provides a systems-level view of disease biology. However, utility depends on how well you are able to integrate them together.
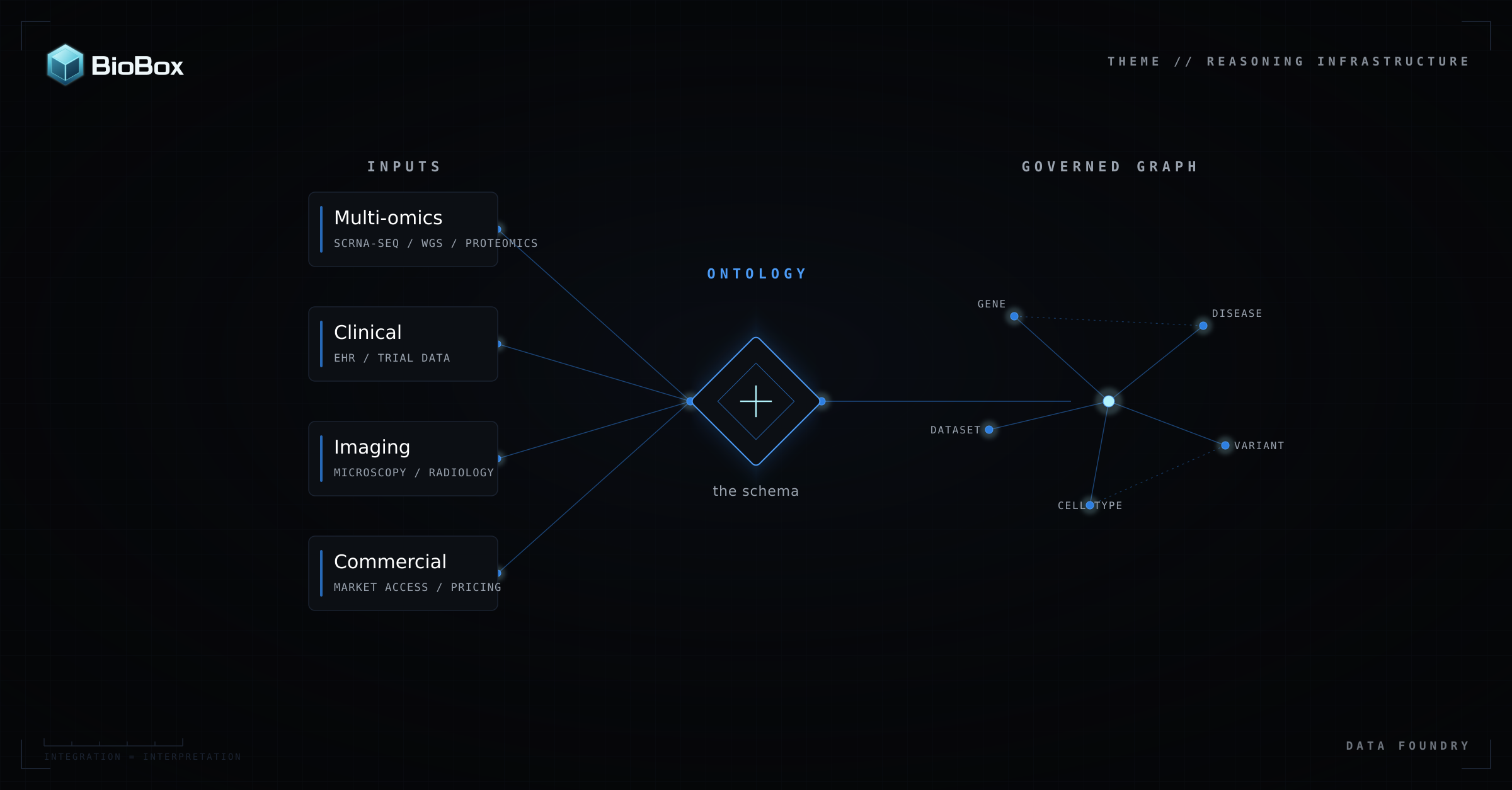
Here’s what it looks like in real world settings:
- Multi-omics: Structured data with annotated experimental metadata. Includes primary, secondary, and tertiary level datasets.
- Clinical Trial Data: Structured and unstructured information.
- Imaging: Microscopy, staining, radiological imaging etc.
- Commercial Data: Market access, SoC, pricing, regulatory.
Integration is not a volume problem
It is tempting to measure integration based on volume. How many datasets are connected? How many records are linked? How much data is annotated? But you can also connect imaging to transcriptomics to clinical outcomes and learn nothing. Integration is good when it lets you ask questions that no single data modality can answer in isolation.
*Does this transcriptional signature correspond to this morphology in this patient population when responding to this treatment?*
The answer to that question exists somewhere in the space between multiple data modalities. Whether you are able to answer this depends on whether you’ve been able to build for those specific connections.
So the real measure is not how much you connected. It is what the connection lets you understand. And what you need to understand is not universal. It is specific to your disease biology, your therapeutic hypothesis, your scientific bet.
To connect two modalities, you have to decide what counts as the same thing across them. When a region in an image and a cluster in single-cell data both describe "tissue," are they the same tissue, at the same resolution, meaningful in the same way? The data does not settle this. Your scientists do. Every one of those decisions is a scientific judgment, and the full set of them has a name: your ontology. It is the schema that says what your data is actually about, and it is where your institution's reading of biology gets written in a form a machine can operate on.
If integration drives interpretation, then a foundation that holds yours has to do three things.
Core Tenets of Multi-Modal Data Foundations
1. Singular Unified Representation of Science
The same word rarely means the same thing twice. For example, “Disease” in a clinical record is a diagnosis code, while in a market access file it could represent a reimbursement category. Since every dataset arrives with its own conclusions, definitions, and criteria, naively connecting them will create logical incoherence.
A unified representation collapses that fragmentation into a singular canonical view. Every entity resolves to one definition, every threshold aligns to one standard. This is the Ontology doing the core work.
2. Modular Composition
The goal is to let the system grow without having to be rebuilt every time. In practice, it means we should begin with the minimum viable ontology. We don’t need to define every possible detail before data starts getting loaded. In fact, this is a common mistake for most semantic projects that reduce adoption and eventually kills the project. Real world use cases prioritize speed. Modularity means we can compartmentalize and load in definitions and data iteratively.
However, a single entry with malformed metadata can corrupt the system. It propagates its errors through every relationship it touches, quietly corrupting analyses far from where it entered. So composition carries a condition: each module must conform to the ontology before it joins. Resolve it against the schema, validate its mappings, confirm what it actually describes. A module that honors the contract strengthens the whole. One that violates it poisons everything connected to it.
3. Change Management and Governance
Science is constantly evolving, and multiple stakeholders across functions rely on this data foundation. We need to update schemas while proactively detecting issues in the underlying foundation. We also need to track incoming changes and evaluate their impact on any assets built on top of the data. For example, when you load or modify a schema, how does it affect decision packages or downstream data assets consumed by other business applications?
There is a second reason this matters, and a regulated organization feels it first. Changing the ontology means changing your institution's scientific position of record. In a GxP, audit-trail world, that has to be deliberate, traceable, and reversible. Governance is what lets the foundation evolve without breaking what it supports: running impact analysis before a change rather than discovering its effects afterward, reverting risky changes, enforcing authorization so the people altering definitions are the ones entitled to, and keeping the full history auditable. A foundation you can trust over time is not one that never changes. It is one that changes under control.
BioBox Approach: The Data Foundry
The Data Foundry is the data foundation layer of DecisionOS. It is where a team configures a custom knowledge graph and the ontology that defines it, structuring multi-modal scientific data into one governed representation rather than forcing it into a fixed model. Public consortium data, proprietary multi-omic sequencing, and ELNs are integrated through the UI or SDKs and resolved into the same graph.
In the life sciences, three capabilities determine whether that foundation can be trusted as the science and the data change, and the Data Foundry is built around each one:
Ontology management: The schema is a custom ontology that reflects how your organization's science is organized and how its evidence connects. It is the shared structure through which all data and reasoning flow, so every entity resolves to one definition regardless of which dataset it came from. Defining and evolving that ontology is how an institution's scientific framework becomes the operating structure of its data, rather than documentation that sits beside it.
Change management: Science does not hold still, and neither does the schema. As definitions are revised and new data and modalities are added, the Data Foundry updates the knowledge graph without breaking the models, reports, and decisions built on top of it. Every change is versioned and tracked, so the foundation evolves deliberately and its full history stays auditable instead of accumulating silent drift.
Impact analysis: Because every model and decision package inherits the ontology, a schema change is never local. Before a change is applied, the Data Foundry surfaces what it will affect downstream, including which decision packages, data assets, and dependent applications are touched, so the consequences are known in advance rather than discovered after a decision has shipped. This is what makes change safe at enterprise scale: the full scope of a definition change is visible before it is committed.
The result is a single governed representation of biological knowledge that discovery, translational, and program teams work from at once, with context and provenance preserved as data moves from generation to decision. That is the difference between a database that stores multi-modal data and a foundation that encodes what it means.
Example: Combining multi-omic data
BioBox provides modular data packages built from public data sources and ontologies that can be imported to enrich the graph.
Take a team working on idiopathic pulmonary fibrosis. They generate two datasets from two different assays. The first is a single-cell RNA-seq experiment comparing IPF and healthy lung, run through a tertiary differential expression analysis. The second is whole-genome sequencing across an IPF cohort, with annotated variant calls. These are the secondary and tertiary outputs scientists actually work from: a DEG table on one side, a variant table on the other. In a file-based world they are two tables in two formats, and nothing connects them except a scientist who happens to remember that both are about the same gene.
The Data Foundry transposes each file into the knowledge graph. Every dataset enters as a Dataset node that carries its own provenance: the assay, the platform, the comparison, the source. A Data Pack defines how that dataset's observations map to concepts and relationships in your ontology. The observations are not flattened back into rows. Each one becomes structure that extends from the Dataset node.
For the RNA-seq dataset, every differentially expressed gene becomes an observation. It carries its statistics, the log fold change and the adjusted p-value, and it connects to a canonical Gene node. That Gene node is not a string. It is a resolved entity in the ontology, the same node every other dataset points to when it refers to that gene. The metadata resolves the same way. The cell population becomes an edge to a Cell Type node. The condition becomes an edge to a Disease node. The tissue becomes an edge to an anatomy node. Platform, cohort, and comparison resolve alongside them. Every piece of context becomes a relationship to an ontology-backed entity instead of a value trapped in a column.
The variant dataset transposes by the same rules. Each variant becomes a resolved Variant node, and its association becomes an observation that is associated with a Disease node and acts through a Gene node. Different assay, different file, different observation type, same ontology underneath.
Now the two datasets meet. MUC5B is upregulated in club cells in IPF from the first. The MUC5B promoter variant is associated with IPF risk from the second. Both observations point at the same MUC5B Gene node. Both point at the same IPF Disease node. The link between a transcriptional signal and a genetic risk allele is no longer a fact living in someone's head. It is an edge in the graph, and it traces back to the exact file and analysis that produced it.
Increased resolution allows for more complex and realistic biological queries. Query by a gene entity and you retrieve everything that touches MUC5B, the DEG from single-cell and the variant association from whole-genome sequencing, across both modalities, each traceable to its source. Query by a metadata entity instead, a cell type like club cell or a disease like IPF, and you retrieve every observation resolved to that node, across every dataset and every omics layer ever integrated.
That is the difference between storing multi-modal data and integrating it. The files are still there. The science is now in the connections between them. Together, it captures the scientific judgment of your best scientists.